K-Means and Customer Segmentation
In my previous article, I talked about Customer Segmentation with RFM technique. I will talk about Customer Segmentation again. But, this time, I will use an unsupervised machine learning algorithm: K-Means Clustering.

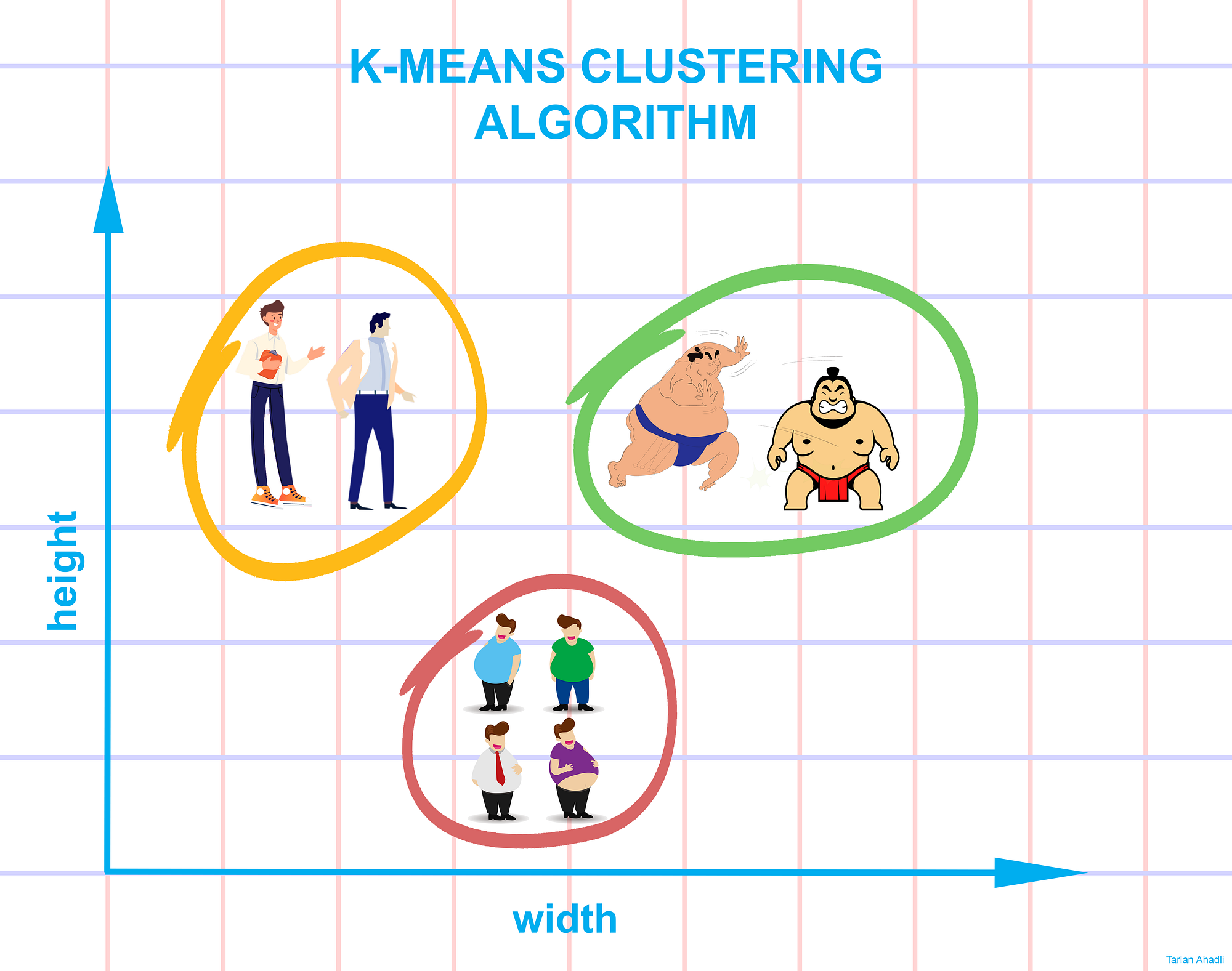
What is K-Means Clustering Algorithm?
K-Means Clustering is an unsupervised learning algorithm that is used to solve the clustering problems in machine learning. This algorithm tries to group similar items in the form of clusters. The number of groups is represented by K. Here K defines the number of pre-defined clusters that need to be created in the process, as if K=2, there will be two clusters.
How to Perform?
To perform K-Means clustering, all data points are grouped into k number of clusters, each of which is represented by its centroids. The centroid of a cluster is often a mean of all data points in that cluster.
The data points in a cluster are closest to the centroids of that cluster. There is a high similarity between data points in a cluster and data points from one cluster is dissimilar to the data points of another cluster. The similarity of the cluster assignments is determined by computing the sum of the squared error (SSE) after the centroids converge. The SSE is defined as the sum of the squared Euclidean distances of each point to its closest centroid. Since this is a measure of error, the objective of k-means is to try to minimize this value.
The steps of K-Means are:

Customer Segmentation with K-Means
We use Online Retail dataset as in the previous article.

Kaggle: https://www.kaggle.com/code/ahmetokanyilmaz/k-means-and-customer-segmentation
Github: https://github.com/aoyilmaz/DataScience_Projects/blob/main/CRM/K-Means/k-means.py

{kind=link}